DIMACS
Project Description
Tumor growth can be modeled as a Galton-Watson process, a branching stochastic process in which cells divide normally, acquire mutations, or die at discrete time steps. Many studies have modeled cancer growth using Galton-Watson processes without consideration of spatial constraints. However, when a cancer cell divides, daughter cells may inhabit different regions than its parent cell; consequently, one would expect that significant cell diffusion occurs during neoplastic growth. Incorporating such spatial dynamics in mathematical models may lead to new insights about the evolution of tumors. Our goal is to develop a mathematical framework for understanding spatiotemporal cancer dynamics.
Weekly Log
-
Week 1
After meeting the other participants and being welcomed into the program, I met with my mentor, Dr. De, to discuss the research I will be doing for the next eight weeks. He described some of the basic mechanisms of neoplastic growth and how stochastic branching process models are used to describe tumor evolution. Then, he stated the question of interest: What mathematical insights can be obtained from stochastic models of cancer which incorporate spatial details? Under his suggestion, I reviewed literature to search for previous analysis of analogous birth-death processes in fields outside of oncology as a starting point. I found a paper which used the theory of birth-death processes to model chemical reactions, and explicated how to completely determine the equations which govern the simple birth-death process [1]. Finally, I finished writing up my introductory presentation Saturday morning.
-
Week 2
I spent most of the first half of the week reading a Python script for a stochastic tumor simulation that Dr. De gave to me. Later in the week I read a little more about stochastic simulation algorithms for diffusion, such as those based on the Smoluchowski equation and on compartments. I am now comparing and contrasting these two modeling methods to determine which will be more useful. Briefly, Smoluchowski is based on Brownian motion and tracks the movement of particles in continuous space at discrete time intervals, while compartmental models discretize the space into compartments which are homogeneous by assumption. Since Smoluchowski diffusion tracks the motion of individual particles, it is more descriptive, but also more computationally intensive.
-
Week 3
I began this week searching for stochastic models of chemotaxis. My idea was that the behavior of bacteria in directed random walks towards food particles would be sparsely analogous to the diffusion of cells away from high concentrations of other cells. While bacteria randomly move in the general direction of a concentration gradient, I reasoned, cells randomly move in the general direction away from other cells. The problem with this reasoning, of course, is that in the chemotaxis example, the system is coupled: as bacteria move towards food particles, they consume them, which decreases the concentration of these particles.
Luckily, one paper that I read in my search for chemotaxis models employed an operator-splitting method to stochastically simulate reaction-diffusion processes. This method could be particularly well justified in the context of neoplastic progression because reactions (cell birth and death) and diffusion (cell migration) are essentially independent processes. Therefore, for the remainder of the week I studied reaction-diffusion partial differential equations to gain a better understanding of which sort of reaction terms could encapsulate tumor growth. I found a few papers on the Fisher-KPP model, which I believe will incorporate the tendency of cells to grow less in more crowded areas.
-
Week 4
One of my main focuses for this week was to understand the stochastic method used in [2]. The algorithm employed an "operator splitting method," in which the reaction and diffusion terms in a reaction-diffusion process are simulated using separate methods.
The algorithm included components from both the Gillespie Multi-Particle method as well as Brownian dynamics. Basically, the idea is that during each time-step, it determines whether the system is in a reaction-controlled, diffusion-controlled, or intermediate state. Then, the next time step is set based on the state type. During each time step, the (discrete) position of each particle is determined by Brownian motion, and then the reactions that occur are determined by the Gillespie algorithm.
-
Week 5
This week I began writing a Python script to simulate tumor growth using the operator-splitting method in [2]. I've had a few problems to resolve so far:
- The simulation discretizes 3D (or 2D) space, and for each time step, determines which reactions occur at each gridpoint. This could prove extremely computationally intensive. For instance, if there are 1000 gridpoints per dimension (a reasonable estimate since we would first like to simulate tumor without boundary constraints) then this would require a billion computations per time step. My solution was to represent the discretized space as a Python dictionary, where keys were tuples which represented coordinates and values were cell objects, which contained information about cells such as the continuous coordinates, the type of cell, etc. That way, I could only consider discrete coordinates which contained cells, thus iterating over a much smaller number of elements.
- In order to implement a stochastic simulation algorithm for a reaction process, it is necessary to have a propensity function, which gives the probability that a reaction will occur in a small interval $[t, t + dt]$. I wanted to show that the propensity function which I chose would recover the deterministic logistic equation in the theoretical mean. I first tried to construct a formal proof by adapting a method I had previously seen from the manipulating the chemical master equation, but ended up with an expression involving expectations of functions: $$ \frac{d \mathbb{E}[A(t)]}{dt} = b \cdot \mathbb{E}\left[ A(t) \cdot \left(1 - \frac{A(t)}{K} \right) \right]$$ Unsure of how to proceed, I next tried to determine the mean by solving the system of equations directly. Although it first seemed like this method would work, I quickly realized that the solution equations for the probability function $p_n(t) := \mathbb{P}(A(t) = n)$ quickly became complex. At this point, I decided to run simulations to quickly verify that my intuition was correct. I ran 100 simulations and plotted the result against the the solution of the corresponding logistic equation. To my surprise, I noticed that the logistic equation tended to overestimate the average simulation, showing me that I was incorrect to assume this relationship between the stochastic birth-death process and its deterministic doppelganger.
-
Week 6
I spent the first half of this week finishing up my simulation script, but the second half debugging subsequent errors that I had in my code. Here are a few highlights:
- Only one cell was generated, which simply moved in random directions throughout space. I later realized that this was because I had incorrectly typed the propensity functions of the reactions.
- When the cells diffused, it was possible for the grid to change size during iteration. To give an example of how this could happen, one could consider a 2D grid containing two cells starting at the origin. During diffusion, the algorithm traverses the grid, moving each cell at each gridpoint in the grid. For instance, it could move a cell from the origin to the point $(2,3)$, but then there would be two gridpoints, $(0,0)$ and $(2,3)$, so now there are two gridpoints. Python reasonably gets angry when an iterable changes size during iteration like this. The clear solution is to create a new "temp" grid object and store the coordinates of each cell after diffusion to this grid. However, doing this at each time step is memory-intensive, a problem that I was hoping to avoid.
-
Week 7
After smoothing out the issues in my code over the weekend, I was able to produce visualizations of the tumor progression. My code could produce visualizations of simulated tumor growth restricted to two dimensions as well as of cross-sections of unrestricted 3D growth. Parameters were selected to produce realistic outputs. Since one of my goals was to determine which factors impact intratumor heterogeneity, I altered certain parameters in the model and compared the output visualizations to a control group. Below are a few animations.
I also created a github account and repository for my work, which is available here.
On Friday, I gave my final presentation for the REU program, which is available below under the Presentations heading.
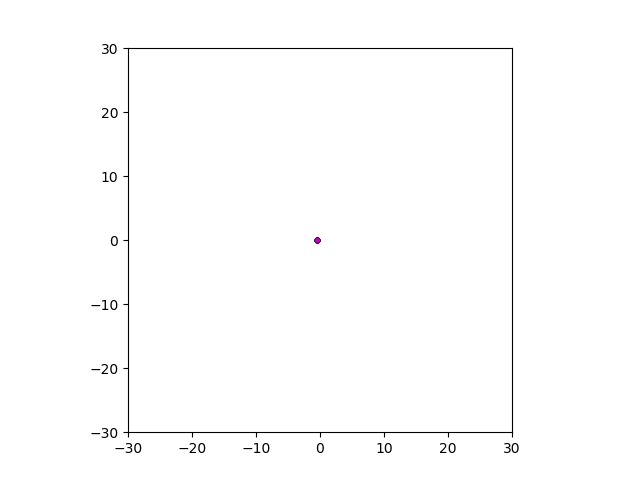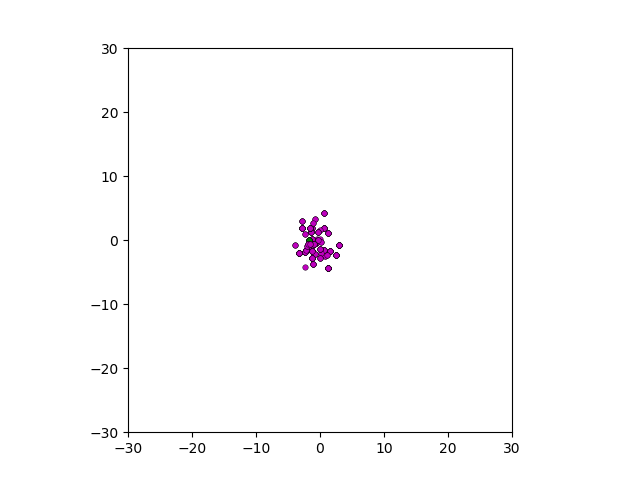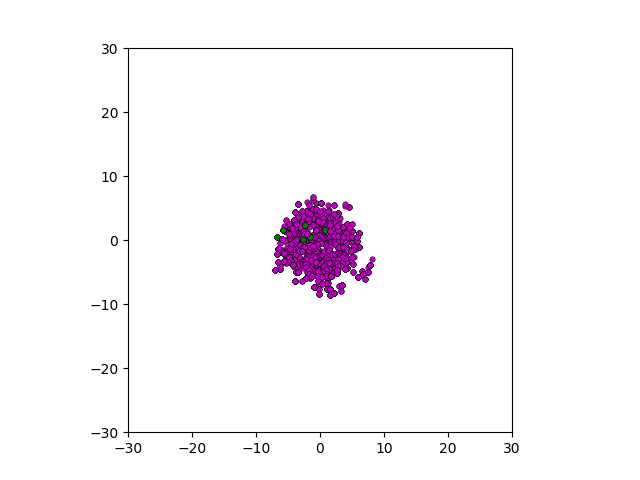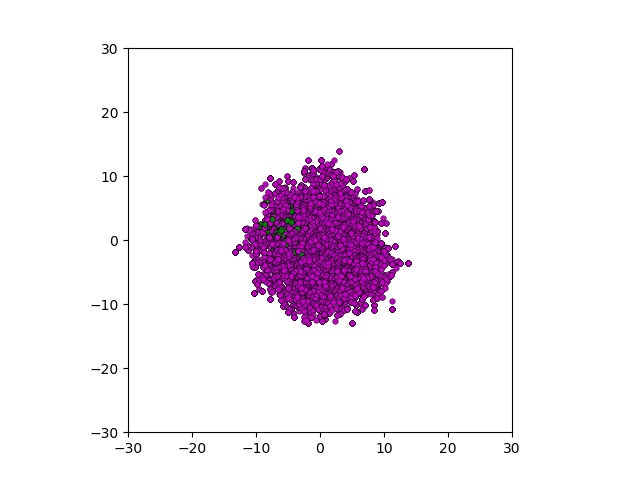
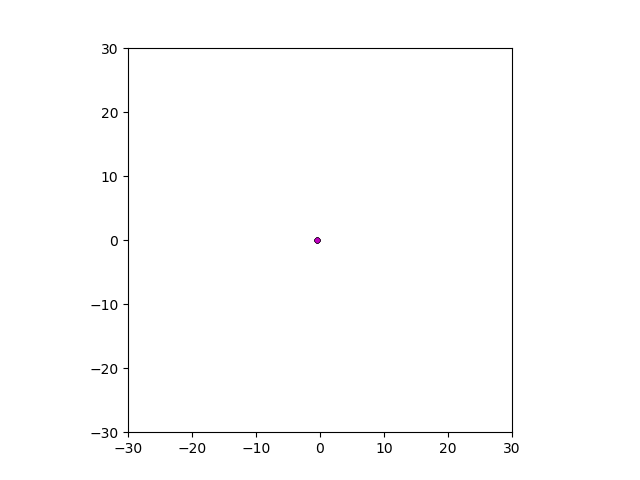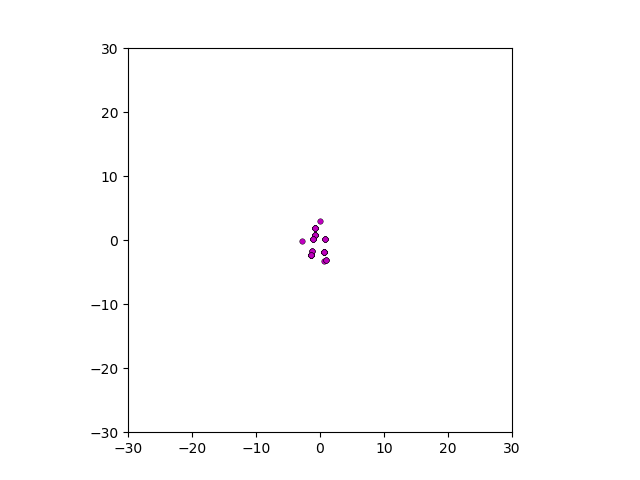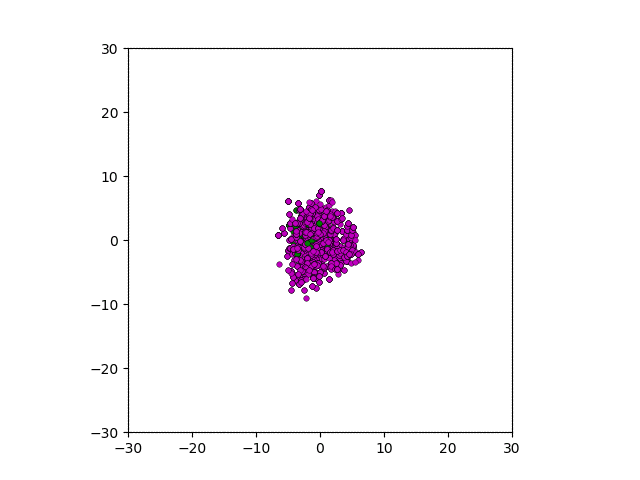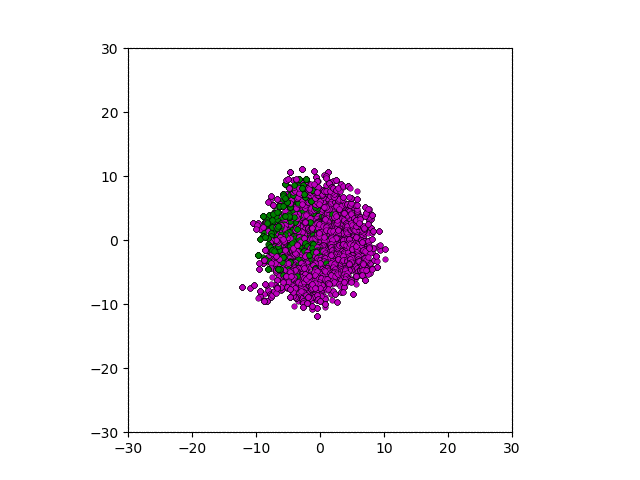
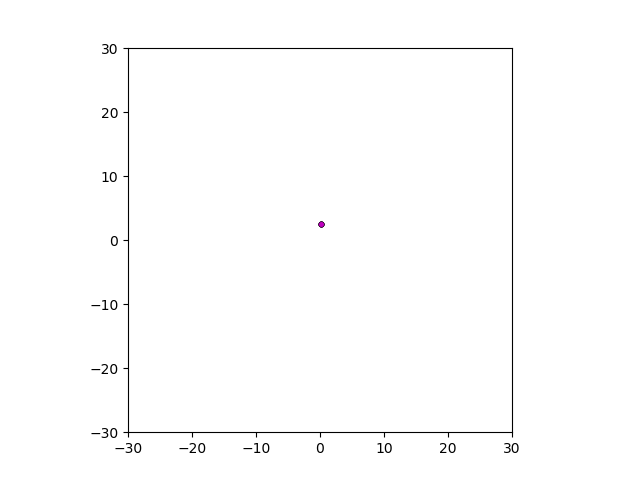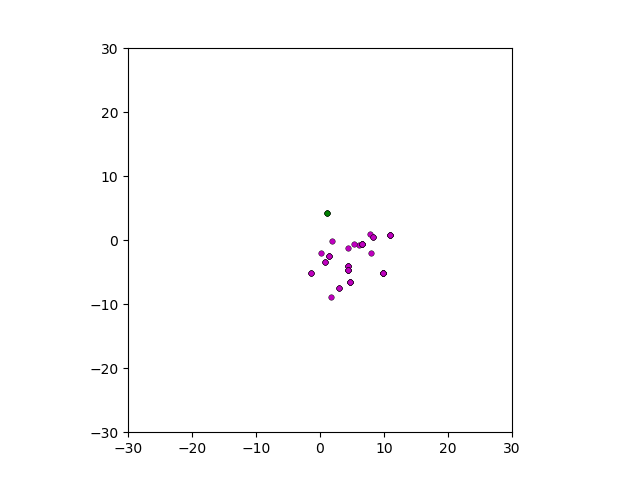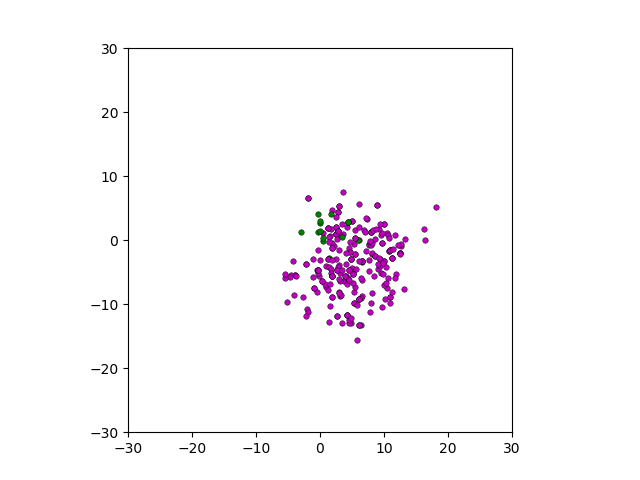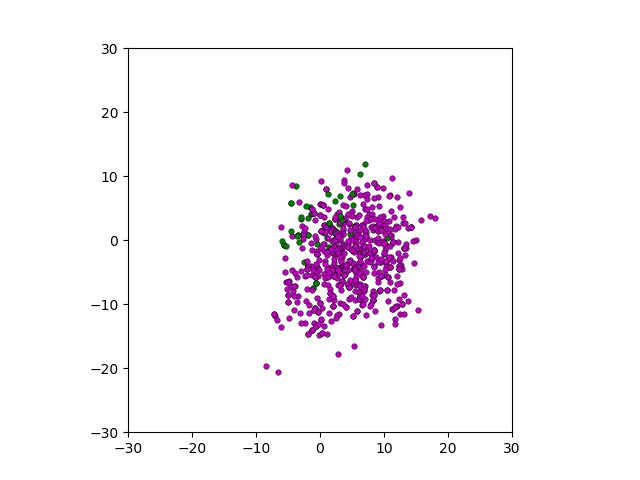
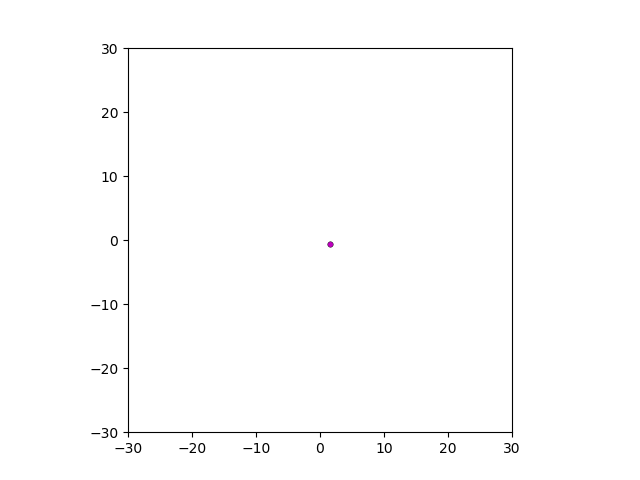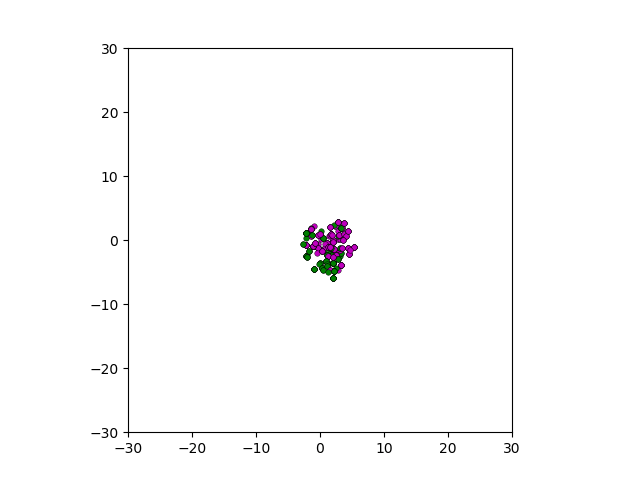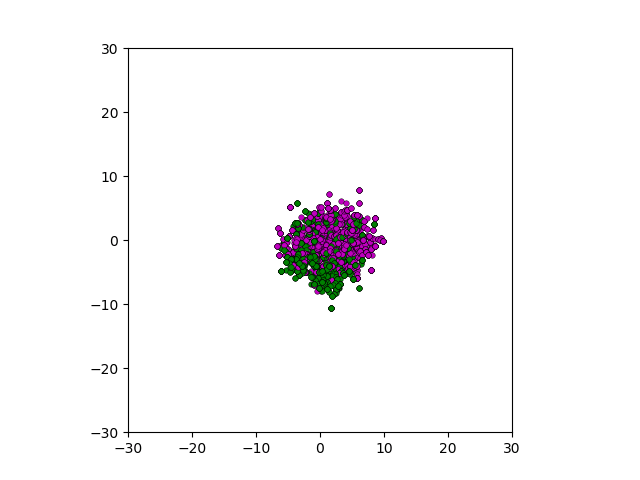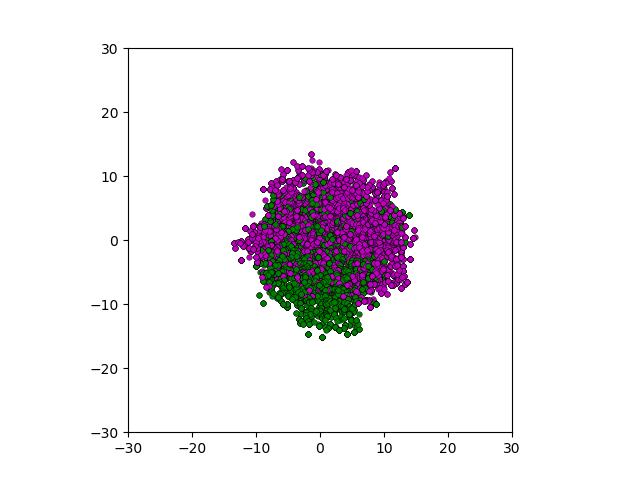
Figure: Top left: control group. Magenta represents initial clone whereas green cells are mutant clones. Top right: Increased growth rate for mutant cells. Bottom left: Increased diffusion rate for all cells. Bottom right: Mutation occurs earlier in the neoplastic progression.
Week 8
This week I was looking at different metrics for assessing diversity across sites, termed "beta-diversity" by ecologist G.H. Whittaker in the 1960s [3]. One paper I read determined estimates for diversity of amphibian, avian, and mammilian species in Western Hemisphere regions by applying logistic regression over gridpoints within a specified radius [4]. To paraphrase, the index of dissimilarity between two sites i and j is given by $$\beta_{\textrm{sim}}^{(i,j)} = \frac{\min(q_{i}, q_{j})}{s_{ij} + \min(q_{i}, q_{j})}$$ where $q_{i}$ is the number of species unique to cell i and $s_{ij}$ is the total number of species present in both cell i and cell j. For each site, using all of the similarity indices $\beta_{\textrm{sim}}^{(i,j)}$ within a threshold radius, a least-squares approximation is performed for the functional form $$ \log \left( \frac{1-\beta_{\textrm{sim}}}{\beta_{\textrm{sim}}} \right) = I + r \log(d)$$ where d is the distance between cells, and I and r are fitted intercept and slope coefficients, respectively.
One problem with this method for our analysis is that our simulation will only handle at most 3 or 4 different cell species. Measures of similarity will therefore only take a small set of potential values, and measures of diversity will likely be somewhat homogenous between sites. Furthermore, the index does not take into account the quantity of each species at a site. For a somewhat hyperbolic example, if there is 1 blue cell and 1000 red cells at site 1 and 1000 blue cells and 2 red cells at site 2, the model will render the two sites as perfectly similar, dispite the obvious incongruence between the sites. Therefore, I looked into different measurements of diversity.
One such measure of compositional differences between two sites i and j is the Bray-Curtis dissimilarity, which is given by $$ BC_{ij} = 1 - \frac{2C_{ij}}{S_{i} + S_{j}}$$ Here, $S_{i}$ is the total number of species at site i, and $C_{ij}$ is the sum, over all species, of the lesser values of species counts at each site. For instance, if site 1 has 3 alpacas, 2 baboons, and 1 camel, whereas site 2 has 2 alpacas and 4 camels, $BC_{ij}$ is given by $$ \min(3,2) + \min(2,0) + \min(1,4) = 3. $$ Since this factor takes into account the number of each species, it avoids the issue I would have using the model in [3]. I am hoping to apply the logistic regression idea in [3] but with the Bray-Curtis index, which avoids the previously mentioned problems.
Week 9
This week was the final week of the program, and I spent the majority of my time writing my final paper. The DIMACS REU has been a fantastic experience for me! I'd like to thank Dr. Subhajyoti De, my mentor at the Cancer Institute of New Jersey, as well as the coordinators of the DIMACS REU program: Lazaros Gallos, Parker Hund, and Peter Korcsok.
References
- Radek Erban, Jonathan Chapman, and Philip Maini. A Practical Guide to Stochastic Simulations of Reaction-Diffusion Processes. 2007.
- Choi, T., Maruya, M. R.,, Tartakovsky, D. M., & Subramaniam, S. (2012). Stochastic operator-splitting method for reaction-diffusion systems. Journal of chemical physics, 137(18), 184102.
- Whittaker, R. H. (1960). Vegetation of the Siskiyou mountains, Oregon and California. Ecological monographs, 30(3), 279-338.
- McKnight, M. W., White, P. S., McDonald, R. I., Lamoreux, J. F., Sechrest, W., Ridgely, R. S., & Stuart, S. N. (2007). Putting beta-diversity on the map: broad-scale congruence and coincidence in the extremes. PLoS biology, 5(10), e272.
Final paper
Here is a preview of the report I submitted to complete the REU. Feel free to email me to request the document in full.