2021 DIMACS REU Proposed Project Descriptions
Please revisit this page frequently, since additional projects may be posted through January. Your application, including your preference for the offered projects, can be updated by using the link received after your registration.
The projects are indicative of the research planned by the mentors, but may be modified by the time that the REU starts.
*Note that you must be a U.S. Citizen or Permanent Resident to be eligible for these projects.
The Minimum Circuit Size Problem
Project #: DC2021-01
Mentor: Eric Allender, Computer Science
Abstract: The Minimum Circuit Size Problem (MCSP) is a computational problem in NP that is widely believed to be hard to compute, although many researchers suspect that it is NOT NP-complete. However, there is currently only weak evidence to support this suspicion. This REU project will endeavor to find stronger evidence, of the form "If MCSP is NP-complete, then something weird happens". Another possible direction involves clarifying the relative complexity of MCSP and other candidate NP-Intermediate problems. The PI has recently proved some new lower bounds on the complexity of MCSP and related problems, and it should be possible to build on this recent progress. The PI has previously supervised research with REU students on this topic which has led to publications, and there is more work to be done, which should be accessible to an REU student.
References:
Eric Allender, Rahul Ilango, Neekon Vafa: The Non-Hardness of Approximating Circuit Size, Proc. 14th International Computer Science Symposium in Russia (CSR 2019), Lecture Notes in Computer Science 11532, pp. 13-24.
Eric Allender, Joshua Grochow, Dieter van Melkebeek, Cristopher Moore, and Andrew Morgan: Minimum Circuit Size, Graph Isomorphism and Related Problems, SIAM Journal on Computing, Vol. 47(4), 2018, 1339-1372.
Eric Allender and Shuichi Hirahara: New Insights on the (Non-)Hardness of Circuit Minimization and Related Problems, ACM Transactions on Computation Theory (ToCT), 11,4 (2019) 27:1-27:27.
Eric Allender, Dhiraj Holden, and Valentine Kabanets: The Minimum Oracle Circuit Size Problem. Computational Complexity 26 (2017) 469-496.
Eric Allender and Bireswar Das: Zero Knowledge and Circuit Minimization. Information and Computation, 256 (2017) 2-8.
Cody D. Murray and Ryan Williams: On the (Non) NP-Hardness of Computing Circuit Complexity, Theory of Computing, 13 (2017) 1-22.
Michael Rudow: Discrete Logarithm and Minimum Circuit Size, Information Processing Letters 128 (2017) 1-4.
Machine learning for SAT-solving heuristics
Project #: DC2021-02
Mentor: Periklis Papakonstantinou, Management Science and Information Systems
Abstract: This project brings ideas from machine learning in understanding one of the most difficult questions in optimization (including theoretical optimization and its intersection with Computational Complexity).
Within the last 25 years, we progressed from solving SAT on at most 200 variables to instances involving millions of variables and clauses, which made SAT-solvers ubiquitous optimization tools. SAT-solvers are today the standard tools for solving constraint satisfaction problems. A wealth of problems from VLSI design and verification, motion and planning, cryptanalysis, and various other areas are encoded as SAT formulas and solved with the help of competitive SAT-solvers. Besides the empirical analysis of SAT-solvers, their theoretical properties are poorly understood. The proposed research project is an excellent opportunity for students new to research to explore a variety of mathematical questions ranging from "simple" to "tough". The project aims to be an exciting blend of combinatorics, machine learning, and optimization.
Project goal: the student should work in predicting several features of SAT-heuristics based on computation history. For example, a Random Walk heuristic (i.e. an algorithm that solves SAT by randomly flipping variables) may or may not terminate in a given/fixed number of steps. However, when one looks at its computation we conjecture that there are computational patterns that reveal whether the specific heuristic will succeed or not. The student should bring in the study of this phenomena machine learning and other data science tools (in particular visualization tools) in analyzing such possible patterns. Finally, and if time permits we will proceed in devising new theories for the analysis of SAT heuristics and building new ones.
Matrix and Tensor Algebra - Neural Network Applications
Project #: DC2021-03
Mentor: Shashanka Ubaru, IBM Watson Research Center
Abstract: In this project we explore novel linear and tensor algebra machinery in order to obtain new insights in different high-dimensional algebraic constructs and develop new algorithms for efficient computations. The project addresses high-dimensional data problems via two principled and complementary (in terms of representational and computational) thrusts:1. Tensors -Resort to new algebraic constructs that represent and manipulate natively high-dimensional entities, while preserving their multi-dimensional integrity. 2. Matrix sketching -Devise new approximate computational paradigms that provide provable guarantees for the level of precision required by the end-goal objective. The student will get an opportunity to work closely with researchers from IBM Research, to develop and implement new (matrix sketching and/or tensor based) methodology for neural networks. The objective is to design computationally efficient and robust neural network architectures using the above techniques.
Required Skills: Knowledge of matrix and tensor algebra concepts, and deep learning.
Programming: Python (TensorFlow or PyTorch), or Matlab.
Algorithms for reconstructing tensor-structured data
Project #: DC2021-04
Mentor: Anand Sarwate, Electrical and Computer Engineering
Abstract: Tensors are multi-way arrays that generalize matrices (2-way arrays) and arise in a variety of applications such as medical imaging, multimedia data, and chemometrics. A common problem in tensor data is dealing with missing entries in the tensor. Tensor completion algorithms try to fill in this missing data, assuming the tensor has a "simple" structure. In this project, the student researcher will learn about how these problems are formulated and how we define "simple" structures. The project will lead towards implementing some of these algorithms and testing them out on real data from neuroimaging experiments or video reconstruction.
Deterministic Graph Coloring in the Streaming Model
Project #: DC2021-05
Mentor: Sepehr Assadi, Computer Science
Abstract: In the graph semi-streaming model, the edges of a graph on n vertices are arriving one by one in a stream and the algorithm is only allowed to make one pass over this stream and use a memory of O(n*polylog(n)) to process the stream, namely proportional to number of vertices and hence much smaller than the size of the graph which can be Ω(n^2). A recent work of the PI in [1] has shown that a very natural graph coloring problem, namely, Δ+1 coloring of a graph with maximum degree Delta, admits a semi-streaming algorithm in this model. This algorithm however is randomized in a crucial way. The goal of this project is to investigate possibility of obtaining the same (or even somewhat weaker) result using a deterministic algorithm. There are also several intermediate problems, one can explore in this space, for instance, obtaining a deterministic algorithm for finding a "large" independent set of the input graph, say, a one with n/(Δ+1) vertices.
[1] Sepehr Assadi, Yu Chen, Sanjeev Khanna: Sublinear Algorithms for (Δ + 1) Vertex Coloring. SODA 2019: 767-786
Counting Spanning Tress via Vertex-Degrees
Project #: DC2021-06
Mentor: Bhargav Narayanan, Mathematics
Abstract: The problem of counting spanning trees is a well-studied problem with important applications in mathematics and theoretical computer science. For example, one of the more famous results on this topic is Kirchoff's theorem. This project will explore the following basic question: if G is a graph and we know the degrees of its vertices, what can we say about the number of spanning trees G possesses? There are some beautiful conjectures here that we will explore. One of them is Ehrenborg's conjecture Another is a new (conjectural) inequality about the permanent of a non-negative real matrix. As a warm up, try to answer the question here (without looking at the solutions that follow).
Generalizations of financial stock options
Project #: DC2021-07
Mentor: David Pennock, DIMACS
Abstract: We will explore generalizations of financial stock options. These generalizations include exchanges that (1) consolidate all strike prices or expiration dates, (2) combine options on multiple stocks in non-trivial ways, (3) handle millions or billions or strike prices per market, or (4) offer novel user interfaces for defining financial derivatives. We will explore techniques to extract forecasts of stock prices from options prices. We will investigate the application of financial options to sports betting. The student should have knowledge of probability theory and would benefit from knowledge of financial options.
Fair and Strategy-proof Tournament Design
Project #: DC2021-08
Mentor: Ariel Schvartzman, DIMACS & David Pennock, DIMACS
Abstract: Suppose we are given a graph T representing the winners of games in a round-robin sports tournament among n teams (that is, a complete, directed graph, where an edge from team i to team j means i beat j). How should we pick a tournament winner in a fair way? If one team beats all other teams, then the answer is clear: simply pick that team. If no such team exists, we may choose the winningest team or employ a randomized algorithm to pick a winner. However, the teams will be aware of this algorithm and can collude (i.e., fix matches) to manipulate the intended outcome of the algorithm and improve their chances of winning. Can we find algorithms that pick fair winners and also provide enough disincentives for teams to collude? Current models that study these questions are limited: they only consider settings where a single team is picked or where teams colluding assign equal weight to their chances of winning as their collaborators. Can we design fair and collusion-resistant rules in broader models?
Some references:
https://arxiv.org/abs/1605.09733<
https://arxiv.org/abs/1906.03324
Social encounter patterns in human mobility: modeling and analysis
Project #: DC2021-09
Mentor: Jie Gao, Computer Science
Abstract: Technology innovation has enabled the possibility of collecting in large scale real world human mobility trajectories. In this REU project we focus on the encounter events - two individuals are at the same location at the same time - and study fundamental questions on this dynamic network of encounter events. A list of sample questions include: are there interesting properties of this spatial-temporal graph? how fast can information (or infectious diseases) spread through such encounter events? How to build a mathematical model of this dynamic graph? How to protect private, sensitive information from being revealed through the encounter events? Students will have the opportunity to work with real world data and to discover new insights of how people move around and interact with each other.
Data Stories
Project #: DC2021-10
Mentor: James Abello, Computer Science
Abstract: One of the central goals of this project is to imagine ways to free data from the somewhat necessary but "boring" sidebar graphs so that data can interact and express itself with confidence to human interpreters, i.e. providing artifacts that facilitate the creation of "data driven stories".
What makes a story truly data-driven is when the data is the central fuel that drives the narrative. Data can help "narrate" many types of stories. In this project we will initiate the development of a framework to help identify and generate different types of "data stories" similar in spirit to Christopher Booker's seven basic story plots [1,2]. One important project phase will focus on the analysis of a variety of "data stories", in order to identify suitable "story modes", and corresponding "data types and characteristics".
The "story modes" include:
a. Narrations of change over time,
b. Starting big (small) and drilling down (zooming out),
c. Contrasting Highlights,
d. Exploration of questions resulting when two divergent lines of data intersect and one overtakes the other,
e. Dissection of factors that contribute to form the big picture, and
f. Outliers profiling.
The "data types" may include numbers, characters, strings, sets, lists, trees, posets,lattices, graphs, hypergraphs, and simplicial complexes. Depending on the story context, each of these "data types" may possess its own intrinsic characteristics likevalue, visual representability, variety, volume, velocity, volatility, veracity, and provenance. Data types susceptibility to change and their ability to "interact" with other data types may be determinant factors of their "story roles".
Note: This project is part of a larger initiative to build data stories initially funded by the National Science Foundation.
Qualifications: Python, Java Programming, JavaScript Libraries for Visualization like D3.js [3], Classes on Discrete Math, Graph Theory, Algorithms [4], Statistics, and Probability. Some knowledge of low dimensional topology may be helpful but is not necessary. Excellent command of the English language.
References:
[1] http://mediashift.org/2015/06/exploring-the-7-different-types-of-data-stories/
[2] Christopher Booker, The Seven Basic Plots: Why we tell stories, Continuum, 2004
[3] Effective Visualization of Multi-Dimensional Data - A Hands-on Approach, DipanjanSarkar
[4] Algorithms, S. Dasgupta, C. Papadimitriou, U. Vazirani, McGraw Hill, 2008
Deep Learning for Quality Prediction in Metal Additive Manufacturing
Project #: DC2021-11
Mentor: Weihong 'Grace' Guo, Industrial and Systems Engineering
Abstract: Additive manufacturing, or three-dimensional (3D) printing, is a promising technology that enables the direct fabrication of complex shapes and eliminates the waste associated with traditional manufacturing. The wide adoption of 3D printing for functional parts is hampered by the poor understanding of the process-quality causal relationship and the absence of an online data-driven prediction method for part quality. This study aims to develop methods for extracting spatiotemporal patterns from real-time, in-process thermal images and then correlating the patterns with part quality. Possible solutions include statistical methods in spatio-temporal modeling such as the Gaussian processes, and deep learning methods such as CNN and RNN. A desirable novelty in the method is how to incorporate physics knowledge about the manufacturing process into deep learning. The student will have access to 3D printers and multiple measurement systems in the School of Engineering at Rutgers.
Requirements: data analytics, machine learning, python or R
The Curse of Many - Dealing with Combinatorial Challenges in Multi-arm, Multi-Object Robot Manipulation
Project #: DC2021-12
Mentor: Kostas Bekris, Computer Science
Abstract: Robotic arms are increasingly being deployed in logistics or the service industry, where they are often tasked to manipulate and rearrange multiple objects. Planning a robot's motion so that it avoids undesirable collisions, i.e., the robot motion planning problem, is already a computationally hard challenge. The presence of multiple objects or multiple arms introduces additional combinatorial challenges that need to be addressed (task planning). These challenges correspond to identifying the right order of objects to move as well as the proper coordination of multiple arms operating in the same workspace. Current solutions tend to face significant scaling challenges as the number of objects and arms increases.
This REU project will build on state-of-the-art task and motion planning algorithms in this space. It will explore setups where it is possible to identify methods that can deal with the combinatorial explosion as the number of objects and arms increases. For instance, we have shown in existing work that dual-arm tabletop rearrangement of multiple objects can be decomposed into sub-problems that possess efficient polynomial-time approximation algorithms. The key idea is that the optimal solution requires an optimal assignment of objects to arms and an optimal sequence of such combinations of arm-object pairs to be moved. The first subproblem maps to weighted edge-matching on a graph and the sequencing subproblem maps to a traveling salesperson problem. Both these subproblems lead to very efficient solutions that incur bounded suboptimality yet demonstrate substantial gains in computation time and scalability. It shows how using insights from algorithmic research provides useful tools for robotics.
Depending on the student's prior experience and interests, this REU project can involve: (i) exclusively algorithmic design and analysis, and/or (ii) simulation of such problems and algorithmic solutions (e.g., by using popular robotic simulation tools, such as Gazebo or pyBullet and available motion planning software). Depending on progress and through collaboration with PhD students, the results can be transferred on a real system.
Projects in Pure Math
Project #: DC2021-13
Mentor: Faculty of the Math Department, Mathematics
Abstract: The Math REU Coordinator is Prof. Anders Buch. Several projects will be run in 2021 by members of the pure math faculty. Past topics have included Schubert Calculus (Buch), Lie algebras (Lepowsky), mathematical Yang-Mills theory (Woodward), etc. Applicants interested in a project in pure mathematics should list this project in their application and indicate their specific Math interests; further details on the projects will be worked out in the Spring.
Relationships between combinatorial knot invariants
Project #: DC2021-14
Mentor: Kristen Hendricks, Mathematics
Abstract: A knot is an embedding of a circle into the three-dimensional sphere S^3; two knots are said to be concordant if they form the boundary of an annulus (properly) embedded into S^3 x [0,1]. Concordance is an equivalence relation and the knots up to concordance form a group. These are topological notions, but there are many important numerical invariants associated to knots that can be computed algorithmically, such as from presentations of the knot on a grid diagram. In this project we consider two invariants of concordance coming from symplectic geometry that have combinatorial descriptions, and try to give combinatorial reproofs of known relationships between them. Necessary background for this project is linear algebra and abstract algebra; some topology is not necessary but a plus. (Being able to read all the work at the links is not required; they're included for context.)
Problems in dynamical systems
Project #: DC2021-15
Mentor: Konstantin Mischaikow, Mathematics
Abstract: The following projects will be supervised by Prof. Konstantin Mischaikow and members of his group including, 1. Prof. Marcio Gameiro, 2. Prof. Ewerton Vieira, 3. Hill Assistant Prof. Shane Kepley, 4. Hill Assistant Prof. William Cuello
- Identifying bifurcation for combinatorial dynamical systems
- Taking a Step Away from Traditional Analyses for EcologicalModels
- Data-driven Dynamics
- Studying gene regulatory dynamics via sloppy models
For details, please see this pdf file.
Genome folding and function: from DNA base pairs to nucleosome arrays and chromosome
Project #: DC2021-16
Mentor: Wilma Olson, Chemistry and Chemical Biology
Abstract: Despite the astonishing amount of information now known about the sequential makeup and spatial organization of many genomes, there is much to learn about how the vast numbers of DNA base pairs in these systems contribute to their three-dimensional architectures and workings. The chemical structure of DNA contains information that dictates the observed spatial arrangements of base pairs within the double helix and the susceptibilities of different base sequences to interactions with proteins and other molecules. Our group has been developing software to analyze the spatial and energetic codes within known DNA structures and using these data in computational studies of larger nucleic acid systems (1). By representing the DNA bases as sets of geometric objects, we can capture the natural deformability of DNA as well as the structural details of ligand-bound interactions (2). There are now sufficient data to examine the influence of sequence context, i.e., the effects of immediate neighbors, on the apparent motions of the bases and to develop simple functions that capture this information. The observed behavior can be incorporated in computational treatments to improve our understanding of macromolecular systems in which DNA sequence and protein binding play important roles. For example, DNA elements that regulate gene expression often lie far apart along genomic sequences but come close together during genetic processing. The intervening residues form loops, mediated by proteins, which bind at the sequentially distant sites. We have developed methods that take account of both DNA and protein in simulations of loop formation and successfully captured experimental observations (3,4). Our recent studies of long-range communication between regulatory elements on short nucleosome-decorated DNA (5,6) provide a basis for linking the 'local' arrangements of nucleosomes in these systems to higher-order macromolecular structures, such as the looped architectures detected within chromosomes. We are developing new algorithms to characterize the spatial arrangements of nucleosomes and incorporating the collective information in nucleosome-level depictions of chromosomal DNA (7,8). The build-up of structural components in our treatment of DNA and chromatin offers new insight into the stepwise processes that underlie genome organization and processing.
References:
1. Olson, W.K. 2020. "Insights into DNA and chromatin from realistic treatment of the double helix," in Paul Flory's 'Statistical Mechanics of Chain Molecules' Today, A.C.S. Books, Tonelli, A.E. and Patterson, G.D., Eds., American Chemical Society, Washington, D.C., Chapter 9, pp. 143-159.
2. Tolstorukov, M.Y., A.V. Colasanti, D. McCandlish, W.K. Olson and V.B. Zhurkin. 2007. A novel roll-and-slide mechanism of DNA folding in chromatin: implications for nucleosome positioning. J. Mol. Biol. 371:725-738
3. Czapla, L., D. Swigon and W.K. Olson. 2006. Sequence-dependent effects in the cyclization of short DNA. J. Chem. Theor. Comp. 2:685-695.
4. Wei, J., L. Czapla, M.A. Grosner, D. Swigon and W.K. Olson. 2014. DNA topology confers sequence specificity to nonspecific architectural proteins. Proc. Natl. Acad. Sci. USA 111:16742-16747.
5. Nizovtseva, E.V., Todolli, S., Olson, W.K., and Studitsky, V.M. 2017. Towards quantitative analysis of gene regulation by enhancers. Epigenomics 9:1219-1231.
6. Nizovtseva, E.V., Polikanov, Y.S., Kulaeva, O.I., Clauvelin, N., Postnikov, Y.V., Olson, W.K., and Studitsky, V.M. 2019. Opposite effects of histone H1 and HMGN5 protein on distant interactions in chromatin. Mol. Biol. 53:912-921.
7. Clauvelin, N., P. Lo, O.I. Kulaeva, E.V. Nizovtseva, J. Dias, J. Zola, M. Parashar, V. Studitsky and W.K. Olson. 2015. Nucleosome positioning and composition modulate in silico chromatin flexibility. J. Phys.: Condens. Matter 27:064112.
8. Todolli, S., P.J. Perez, N. Clauvelin and W.K. Olson. 2017. Contributions of sequence to the higher-order structures of DNA. Biophys J. 112:416-426.
Deep genomic analysis of tumor specimens
Project #: DC2021-17
Mentor: Hossein Khiabanian, Rutgers Cancer Institute of New Jersey
Abstract: Understanding complexity, dynamics, and stochastic patterns in genomic data - concepts native to physics and mathematics - is critical for elucidating how disease states originate and evolve. The main focus of this project is to use statistical, information theoretic approaches to dissect the cellular and molecular heterogeneity that enables cancer cells to evolve. We use high-throughput DNA sequencing methods, and computationally integrate genetic and clinical data from large cohorts of cancer patients being treated under various precision medicine programs, with the aim to identify markers of Darwinian selection using longitudinal data. Our ultimate goal is to develop novel statistical platforms for fast translation of genomic data into clinical practice.
Proficiency in programming and statistical analysis are essential; knowledge of genomics and biology is not required but highly valued.
Genomic data-guided mathematical modeling of cancer
Project #: DC2021-18
Mentor: Subhajyoti De, Rutgers Cancer Institute of New Jersey
Abstract: Cancer is the second leading cause of death in adults, claiming the lives of more than half a million Americans every year. Tumor starts from a single rogue cell in the body, which becomes defective, and the clones of that initial cell start to grow (or die out), and acquire new mutations depending on certain parameters stochastically; and by the time of detection the tumor has ~109 cells. During treatment, the patient initially responds and the tumor shrinks, but remaining cells inevitably develop mutations that give them drug resistance, and the tumor starts to grow again until the patient dies. It is becoming apparent that computational algorithms and mathematical frameworks can identify subtle patterns in patient profiles, which can help with early detection and personalized treatment, improving their outcome. For instance, we are developing mathematical frameworks to model tumor development and emergence of resistance against cancer drugs, using Galton Watson branching process - an area of stochastic processes, which also has applications in diverse areas (e.g. option pricing, predicting viral outbreak, news propagation on social networks). We are combining mathematical models with clinical data from cancer patients to ask some fundamental questions - (i) how long does it take a tumor to grow, and can we detect cancer early? (ii) can we identify emergence of resistance very early and accordingly change the treatment strategy? The project will aim to develop mathematical frameworks to model tumor growth using branching process.
Proficiency in computer programming (Java, C++, or python), familiarity with probability theory, concepts of stochastic processes, and optimization techniques are required. Knowledge in Biology is not required.
Data-driven precision medicine approaches to cancer
Project #: DC2021-19
Mentor: Subhajyoti De, Rutgers Cancer Institute of New Jersey
Abstract: One in four is expected to develop cancer in their lifetime. No two patients are alike, and we need better strategies to detect cancer early,find right treatment for the patients, and monitor their outcome using a personalized medicine approach. Data science approaches using state-of-the-art computational algorithms and statistical frameworks can identify subtle patterns sifting through large amount of information in patient profiles, which can help with early detection and personalized treatment, improving their outcome. Within the scope of the Precision Medicine Initiative at the Rutgers Cancer Institute, for each patient we have troves of data on genetic mutations, and clinical and pathological reports. We are developing and implementing data science techniques to ask some fundamental questions: (i) can we distinguish aggressive tumor and treat patients accordingly? (ii) can we identify emergence of resistance very early and accordingly change the treatment strategy? The project will aim to develop data science frameworks to perform integrative analysis of cancer genomics and clinical data.
Proficiency in computer programming (Java, C++, or python), statistical analysis software (R or SAS), familiarity with concepts such as linear models, model selection, support vector machines are preferred. Knowledge in Biology is not required.
Informing Decision Makers with Evidence Based Policy Decisions to Stop the Virus, Save Lives and Prepare for the Next Pandemic
Project #: DC2021-20
Mentor: Ava Majlesi, Miller Center for Community Protection & Resilience/Center for Critical Intelligence Studies & Sassi Rajput, Center for Critical Intelligence Studies
Abstract: Students will work on efforts to execute in real time an ongoing strategic assessment of the US response to the COVID-19 pandemic at the federal and state level to identify evidence-based policy decisions that would, if implemented, reverse the current course of the virus.
Statistical inference on infection processes over graphs
Project #: DC2021-21
Mentor: Min Xu, Statistics
Abstract: We can model the diffusion of fake news over social media or the transmission of disease over human contacts as infection processes that spread over background graphs. For example, in the classic Eden model, the infection originates in one node and then, at every iteration, we infect a random neighbor of the set of infected nodes. The goal of this project is to infer the origin of the infection given observations of the background graph and the set of infected nodes.
We take a Bayesian approach and aim to compute the posterior probability of the origin given the observation. We propose to do this by using Markov chain Monte Carlo (MCMC) to sample from the posterior distribution of the unobserved ordering in which the nodes were infected. This is equivalent to performing a random walk on the space of permutations subject to the constraint imposed by the background graph.
A secondary goal is to theoretically analyze how well one can estimate the true patient-zero. If the background graph is a complete graph, then we cannot make any meaningful inference on patient-zero since the perspective of any infected node is exactly the same as any other infected node. If the background graph is a lattice however, then first passage percolation theory shows that our best estimate of patient-zero can get close to the truth.
Graph Cities
Project #: DC2021-22
Mentor: James Abello, Computer Science
Abstract: "Graph Cities" are 3D representations of maximal edge graph partitions. Each connected equivalence class corresponds to a "building" that is formed by stacking graph "Edge Fragments". The number of such graph edge fragments determines the height of the building. The overall number of buildings is the number of equivalence classes in the edge partition.
In this project, REU participants will build "Graph Cities" from data collections containing at least a billion related entity pairs. Each created "City" will come equipped with a "Story" plus an accessible catalogue of its most prominent "locations", "entities", "landmarks", and "Subgraph Motifs". Each discovered motif will be judged according to its "provenance" and a profile that may include measures of "density", "diversity" , "surprise", and "interestingness".

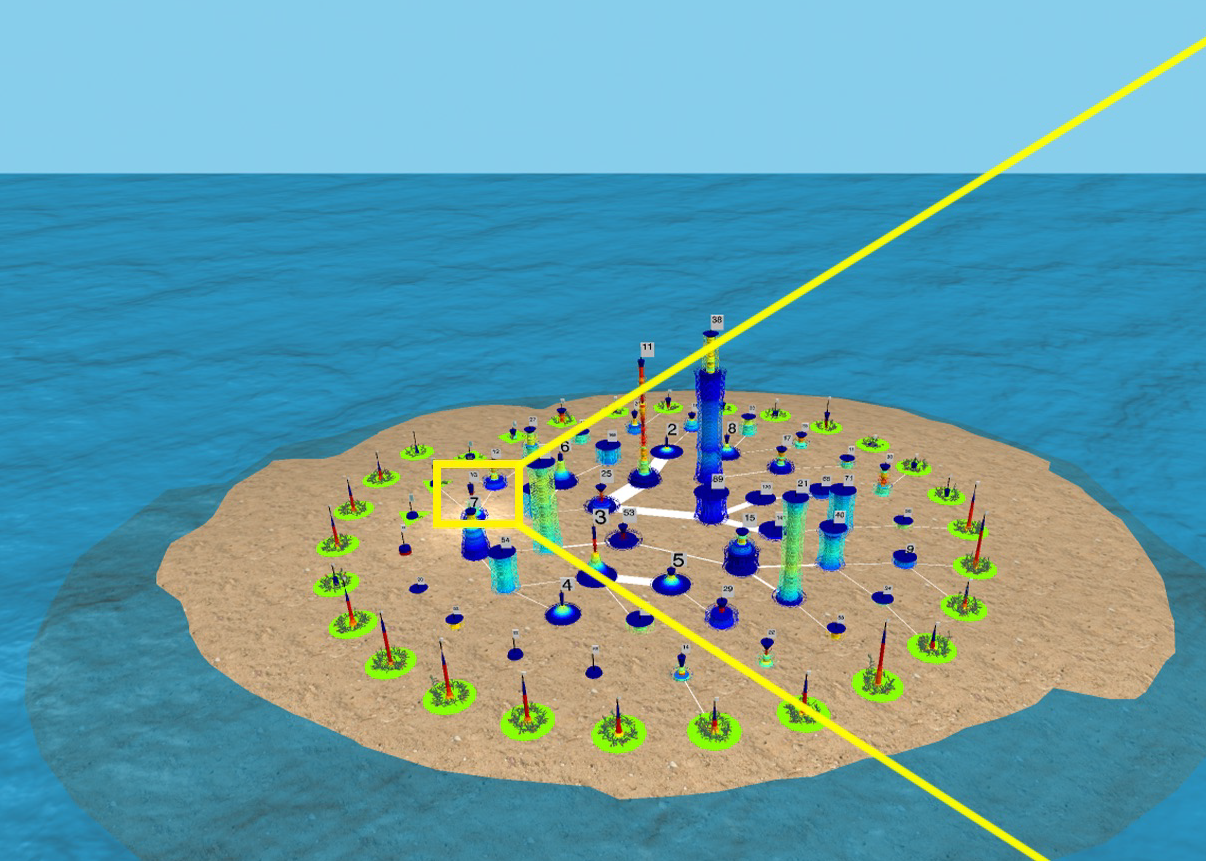
Please read more details in this pdf file.
Pre-Requisites:
Programming Languages: JavaScript and two languages from {Python, Java, C/C++}.
Algorithms/Optimization: A class on Algorithms and a second class in Optimization or Graph Theory.
Reading List: Become familiar with at least 7 papers from the list in the detailed project description before the beginning of the REU.
Mathematical Adventures in One-Dimensional Physics
Project #: DC2021-23
Mentor: Shadi Tahvildar-Zadeh, Mathematics
Abstract: The goal of this long-term, multi-year project is to study, in a simplified setting, a host of foundational issues in physics that are yet to be addressed in a mathematically rigorous way. Among the topics to be considered in 2021 are (1) emergence of Coulomb-type repulsion in electron-photon systems with contact interactions, (2) emission and absorption of photons in one space dimension, (3) entanglement and Bell's Inequality, (4) momentum exchange in Compton scattering. The emphasis will be on mathematical rigor and exact analysis.
Learn to program a high-speed Internet router
Project #: DC2021-24
Mentor: Srinivas Narayana, Computer Science
Abstract: Internet data traffic goes through a series of devices called routers. Routers are customized high-speed computers, meant to move lots of data traffic very quickly from one place to another. In this project, you will learn how to program a real high-speed router (capable of processing multiple Terabits/s), including making the router move traffic to the right place and ensuring that the network paths do not get congested. You will work as part of a larger research effort intended to define mechanisms and policies that carve out network resources to users by programming the routers appropriately.
Familiarity with computer programming and a Linux environment will be required. Please contact Srinivas Narayana (srinivas.narayana@rutgers.edu, https://www.cs.rutgers.edu/~sn624/) if you are interested and/or have questions about the nature of the project.
Data Analysis of COVID-19 patterns
Project #: DC2021-25
Mentor: Lazaros Gallos, DIMACS
Abstract: In this project, the student will analyze data on the evolution of COVID-19 focused on the spatial and temporal patterns of the virus spreading. Using tools from statistical physics, network science, and statistics, the project seeks to understand the special features of this complex behavior and to compare these patterns in different geographical areas.
COVID-19 Micro-Outbreaks and Vaccine Buy-In Visualization Dashboard
Project #: DC2021-26
Mentor: Christie Nelson, Masters of Business and Science in Analytics and CCICADA
Abstract: As part of an ongoing data science project, the student will work to collect data from non-traditional sources to understand trends about covid-19 micro-outbreaks. The student will also work to understand the vaccination process from a data perspective, and try to find correlations with regions/areas that are better/worse with the vaccination process, that the public has better/worse buy-in of wanting to get the vaccine, and other emerging trends. We will create a dashboard of this data as well as other relevant data on a week by week basis, also doing some prediction of future regions of interest.
Modeling of Estimated Numbers of Human Trafficking Victims Using Simulations of Various Prevention Measures
Project #: DC2021-27
Mentor: Christie Nelson, Masters of Business and Science in Analytics and CCICADA
Abstract: Human trafficking is modern day form of slavery. Child trafficking is a particularly tragic part of the large, lucrative criminal enterprise of human trafficking. In 2016, New York City's Administration for Children's Services identified 2,400 child sex trafficking victims in New York City and, in that same year, Texas identified about 79,000 child sex trafficking victims. In 2017, the National Center for Missing and Exploited Children (NCMEC) received more than 10.2 million reports of child exploitation. This number greatly exceeds the current national and global estimates for a recognized pandemic - Covid-19. Most of law enforcement's approach reflects a reactive effort to support the investigation and interdiction of human trafficking. A more proactive effort would be to disrupt human trafficking strategically with evidenced-based predictive models of how traffickers adapt and adopt new methods, tools and channels to market current grooming victims for preventative responses with resources and aid for them. This project will begin to explore prevention methods and their estimated effects on simulated and real data to look for commonalities within other modeling fields.
Morse flow trees
Project #: DC2021-28
Mentor: Christopher Woodward, Mathematics
Abstract: Morse flow trees are combinations of gradient trajectories. They were introduced by Fukaya-Oh and Ekholm to capture the symplectic topology of submanifolds of cotangent bundles. We'll look at the questions like: Are moduli spaces of Morse flow treescompact for very general defining data? What happens when the submanifolds are immersed? Are the moduli spaces of flow treescobordant for different choices?
Diamond operations on directed graphs and factorizations of noncommutative polynomials
Project #: DC2021-29
Mentor: Vladimir Retakh, Mathematics
Abstract: This project is based on my work with Michael Saks "On the rational relationships among pseudo-roots of a non-commutative polynomial". In this paper we introduced a new operation on directed graphs called "diamond operation", investigated properties of this operation and used it to study factorizations of polynomials over noncommutative rings. Further research of diamond operations can be done by using computer experiments. Related algebra problems are new but accessible for students familiar with the first semester of undergraduate abstract algebra.
Assignment mechanisms
Project #: DC2021-30
Mentor: Ron Holzman, Mathematics, Princeton University
Abstract:
 Return to REU Home Page
Return to REU Home PageDIMACS Home Page
DIMACS Contact Information
Page last modified on January 31, 2021.