2017 DIMACS REU Proposed Project Descriptions
Please revisit this page frequently, since additional projects may be posted through January. An application can be updated by using the link received after your registration, where you can update your preference for the offered projects.
*Note that you must be a U.S. Citizen or Permanent Resident to be eligible for these projects.
Spatiotemporal Big Data Analytics for Osteoarthritis Detection
Project #: DC2017-01
Mentor: Weihong 'Grace' Guo, Industrial and Systems Engineering
Abstract: The Osteoarthritis Initiative (OAI) is a multicenter, longitudinal, prospective, observational study of knee osteoarthritis launched by the National Institutes of Health in 2002. The OAI has accumulated a massive amount of clinical and imaging data and biological specimens from thousands of volunteers with risk factors for early knee osteoarthritis for a total of 8 years of follow up. However, these data have not been fully exploited to make optimal decision for the improvement of the prevention and intervention strategies of knee osteoarthritis.
This study focuses on spatiotemporal data analytics for osteoarthritis detection. The goal of this project is to identify clinical biomarkers for early detection of osteoarthrosis and improve the prevention and intervention strategies of knee osteoarthritis used in current clinical practice. Existing methods on spatiotemporal data analytics, dimensionality reduction, feature extraction and selection, and anomaly detection will be reviewed and studied. Familiarity with R is a must.
Requirements:
Statistics, data analytics, R
Sensor Fusion for Process Monitoring and Fault Diagnosis
Project #: DC2017-02
Mentor: Weihong 'Grace' Guo, Industrial and Systems Engineering
Abstract: The wide applications of low-cost and smart sensing devices along with fast and advanced computer systems have resulted in a rich data environment, which makes a large amount of data available in many applications. Sensor signals acquired during the process contain rich information that can be used to facilitate effective monitoring of operational quality, early detection of system anomalies, quick diagnosis of fault root causes, and intelligent system design and control. In discrete manufacturing and many other applications, the sensor measurements provided by online sensing and data capturing technology are time- or spatial-dependent functional data, also called profile data.
In this study we are developing methods for effective monitoring and diagnosis of multi-sensor heterogeneous profile data. The proposed method extracts features from the original profile data and then feeds the features into classifiers to detect faulty operations and recognize fault types. Extensive Matlab simulations will be needed to validate the method and explore properties of the proposed method.
Requirements:
Statistics, math, linear algebra, Matlab
The Minimum Circuit Size Problem: A possible NP-Intermediate Problem
Project #: DC2017-03
Mentor: Eric Allender, Computer Science
Abstract: The Minimum Circuit Size Problem (MCSP) is a computational problem in NP that is widely believed to be hard to compute, although many researchers suspect that it is NOT NP-complete. However, there is currently only weak evidence to support this suspicion. This REU project will endeavor to find stronger evidence, of the form "If MCSP is NP-complete, then something weird happens". Another possible direction involves clarifying the relative complexity of MCSP and other candidate NP-Intermediate problems. The PI has recently proved some new lower bounds on the complexity of MCSP and related problems, and it should be possible to build on this recent progress. The PI has previously supervised research with REU students on this topic which has led to publications, and there is more work to be done, which should be accessible to an REU student.
References:
- Eric Allender, Dhiraj Holden, Valentine Kabanets: The Minimum Oracle Circuit Size Problem. STACS 2015: 21-33 (Expanded version accepted to the journal Computational Complexity.)
- Eric Allender, Bireswar Das: Zero Knowledge and Circuit Minimization. MFCS (2) 2014: 25-32 (Expanded version accepted to the journal Information and Computation.)
- Cody D. Murray, Richard Ryan Williams: On the (Non) NP-Hardness of Computing Circuit Complexity. Conference on Computational Complexity 2015: 365-380
- Michael Rudow: Discrete Logarithm and Minimum Circuit Size, ECCC Technical Report TR16-108.
Toward the Design Optimization of Multi-Robot Systems
Project #: DC2017-04
Mentor: Jingjin Yu, Computer Science
Abstract: Multi-robot and multi-vehicle systems have begun to prove their utility in recent years, with the most prominent example being the automation of
warehouse systems by Amazon (see www.amazonrobotics.com, www.youtube.com/watch?v=Fr6Rco5A9SM). Other examples include autonomous vehicular systems and autonomous farming robots (www.public.harvestai.com). A key factor in rendering multi-robot systems more efficient is the opimization of the design of both the system (e.g., a "road network" for the robots or vehicles) and the algorithms for routing the robots within the system. As an everyday example, recent years have seen the rise of traffic circles to alleviate congestions at road intersections. These structures
make it unnecessary for cars to wait for traffic signals and at the same time allows the card to avoid delay from using stop signs due to the start and stop of vehicles. There is a deeper connection here: the design of the system critically impacts the computational complexity of routing
robots/vehicle through the system [1].
In this REU project, the student will explore the interplay between the system design and routing algorithms in optimizing the throughput of multi-robot systems. Depending on the student's background and preference, theoretical or practical aspects (or both) of the problem may be explore
d. At the theoretical end, one will explore the structure induced by the problem and how it may be exploited. At the more experimental end, simulation and experimental studies (https://youtu.be/n9DOtgHHyGY and [2]) may be carried out to gain empirical understanding of the structural behavior of multi-robot systems.
References:
[1] J. Yu. Intractability of Optimal Multi-Robot Path Planning on Planar Graphs . IEEE Robotics and Automation Letters
[2] J. Yu and Daniela Rus. Pebble Motion on Graphs with Rotations: Efficient Feasibility Tests and Planning Algorithms. In Algorithmic Found
ations of Robotics XI, Springer Tracts in Advanced Robotics (STAR), Vol 107, page(s): 729-746, 2015. Video: https://youtu.be/eg3tKIv2eiU
Machine learning from multimodal data
Project #: DC2017-05
Mentor: Waheed Bajwa, Electrical and Computer Engineering
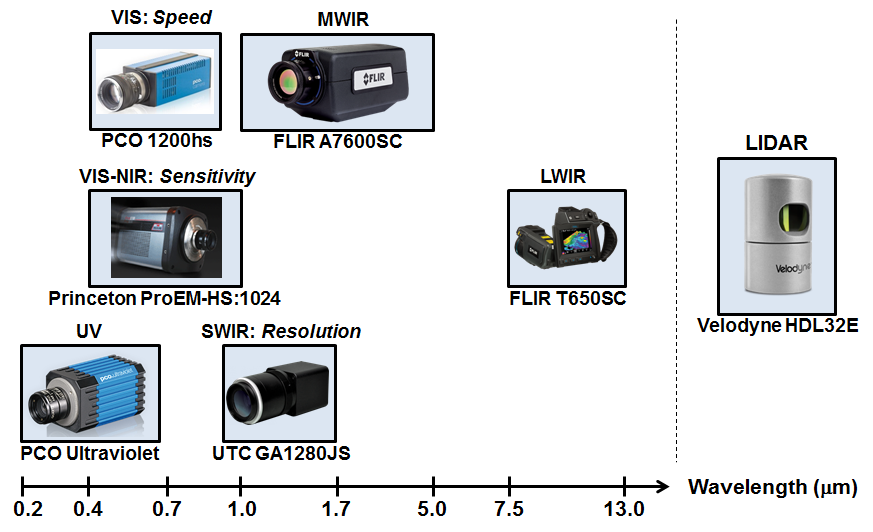
Abstract: Traditionally, many applications in machine learning, ranging from object detection and classification to human activity recognition and surveillance, have relied on Red-Green-Blue (RGB) images and videos for decision making. Recent advances in sensor technology, however, have enabled us to gather multimodal imaging and video data that goes beyond simple RGB data; examples of such data include ultraviolet (UV), infrared (IR), and LIDAR data. While one expects that joint exploitation of these multimodal data would lead to better outcomes, most machine learning algorithms are incapable of such joint exploitation. The INSPIRE lab at Rutgers ECE has received government funding to procure sensors that enable acquisition of data in seven different modalities (see the picture below). The goal of this REU project is to curate datasets using these sensors and develop machine learning algorithms for exploitation of these multimodal datasets for applications such as object detection, classification, andhuman activity recognition.
Requirements
Students should:
- Be enrolled in electrical engineering, computer science, mathematics, statistics, or a related discipline. Have taken courses like linear algebra, probability, and programming; an introductory course in machine learning will be considered a plus.
- Have expertise in Python, Matlab, R, or C/C++; the preferred language for this project is Python and Matlab.
- Be comfortable with handling imaging and LIDAR devices and curating multimodal datasets.
Testing properties of dynamic graphs
Project #: DC2017-06
Mentor: Periklis Papakonstantinou, Management Science and Information Systems
Abstract: Suppose that there is a collection of Very Big Data Objects (VBDO). For instance, a boolean function over 1000 bits
(this has 21000 different entries), or a very big social network graph, or a mathematical formalization of your
favorite computational biology object. Can we test whether such a very big object has a desired property or not by just
sampling a small number of each entries/description bits?
The area of property testing is one of the most successful and fruitful areas of the theory of computing. It has given complete answers to a number of important questions including answers about properties of very big graphs. Complete means that in most cases we know the best sampling protocol (property testing algorithm) and that this is really the best (i.e. we also have a matching lower bound about all possible testing algorithms). This project revisits some of the most important (i.e. of importance for *practical* Big Data analytics) when the parameter of time is part of the problem. This is the actual interest of practitioners, whereas at the same time we have a splendid opportunity to incorporate new mathematical tools in approaching property testing problems.
This project does require some level of mathematical maturity and good knowledge of basic probability and combinatorics.
Excitement for algorithms and their modern applications, as in e.g. computation over big data, is necessary.
Multi-stream algorithms: design and analysis
Project #: DC2017-07
Mentor: Periklis Papakonstantinou, Management Science and Information Systems
Abstract: The streaming model is the prototypical mathematical formalization for analyzing Massive Datasets. In the classical streaming model the data elements arrive one-by-one for a processor to compute. This processor is limited to use a tiny small local memory (compared to
the total number of elements), where it keeps track of what happened. Typically, the memory size is poly-logarithmic in the stream size. Surprisingly, there are many interesting problems that can be solved in the streaming model.
In 2009 (see below [1]) a seminal research article introduced the multi-stream model and initiated the investigation of its limitations. The multi-stream model uses two (or more) streams, which the algorithm can scan a very small number of times, e.g. 2 or 3. Each stream can be thought t
o correspond to a hard disk-array. Thus, the study of the multi-stream model blends perfectly theory and practice.
There are several important works studying limitations of multi-stream algorithms. In contrast, this project proposes to study algorithms (practical constructions). Some first algorithmic techniques were developed in an article [2] published a year ago, which regards cryptographic constructions in the multi-stream model. Now, we propose the study of more elementary combinatorial problems and algorithms. These problems include computation and approximation of linear algebra problems.
This project does not require (neither will involve) knowledge in cryptography. It does require though some level of mathematical maturity and good knowledge of basic probability, linear algebra, and combinatorics, and excitement for algorithms and their modern applications as in e.g. computation over big data.
References:
[1] Martin Grohe, Andre Hernich, Nicole Schweikardt:
Lower bounds for processing data with few random accesses to external memory. Journal of ACM, 2009
[2] Periklis A. Papakonstantinou, Guang Yang: Cryptography with Streaming Algorithms. CRYPTO, 2014
DNA Sequence and Genomic Organization
Project #: DC2017-08
Mentor: Wilma Olson, Chemistry and Chemical Biology
Abstract: Despite the astonishing amount of information now known about the sequential make-up and spatial organization of genomic DNA, there is much to learn about how the vast numbers of base pairs contribute to the three-dimensional architectures and workings of long, spatially constrained double-helical molecules. The detailed molecular structures of DNA with tens of base pairs point to various sequence-dependent spatial and energetic codes underlying the three-dimensional organization of the double helix and its susceptibility to interactions with proteins and other molecules. These data serve as starting points for more coarse-grained treatments of DNA and chromatin at the mesoscale level, chains typically made up of hundreds to thousands of deformable repeating units and modeled by potentials that build upon the atomic-level information. Our group is working to understand how nucleotide sequence guides the three-dimensional genomic landscape at various levels of spatial organization, starting with the constituent base pairs and culminating with the large-scale folding and dynamics of chromosomal fragments. The research entails applications of mathematics to the characterization and simulation of molecular structures at various levels of detail. The following articles are representative of the approaches used in the work:
- Olson et al (1998) DNA sequence-dependent deformability deduced from protein-DNA crystal complexes. Proc Natl Acad Sci USA 95:11163
- Coleman et al (2003) Theory of sequence-dependent DNA elasticity. J Chem Phys 118:7127
- Czapla et al (2006) Sequence-dependent Monte Carlo simulations of DNA ring closure. J Chem Theor Comp 2, 685
- Britton et al (2009) Two perspectives on the twist of DNA. J Chem Phys131:245101
- Clauvelin et al (2012) Characterization of the geometry and topology of DNA pictured as a discrete collection of atoms. J Chem Theor Comp 8:1092
- Clauvelin et al (2015) Nucleosome positioning and composition modulate in silico chromatin flexibility. J Phys: Condens Matter 27:064112
Pan-cancer longitudinal analyses of tumor evolutionary pattern
Project #: DC2017-09
Mentor: Hossein Khiabanian, Rutgers Cancer Institute of New Jersey
Abstract: The focus of our lab at Rutgers Cancer Institute's Center for Systems and Computational Biology is on developing mathematical methods to understand the underlying genetics of human neoplasms. We use high-throughput sequencing methods, and integrate genetic and clinical data to identify prognostic markers and actionable drivers of tumor evolution. Our principal hypothesis is that drug resistance emerges from changing tumor evolutionary patterns. To test this, we will mine the large cohorts of cancer patients being treated under various precision medicine initiatives at Rutgers. We aim to identify markers of selection, study the dynamics of tumor heterogeneity, and investigate the evolutionary mechanism of therapeutic resistance using longitudinal genomic data. Our goal is to develop a novel statistical platform for fast translation of genomic data into clinical practice. This integrated pipeline will increase the speed with which patients can be assessed for potential therapies, contributing significantly to combating drug resistance and increasing positive outcomes.
Genomic data-guided mathematical modeling of cancer
Project #: DC2017-10
Mentor: Subhajyoti De, Rutgers Cancer Institute of New Jersey
Abstract: Cancer is the second leading cause of death in adults, claiming the lives of more than half a million Americans every year. Tumor starts from a single rogue cell in the body, which becomes defective, and the clones of that initial cell start to grow (or die out), and acquire new mutations depending on certain parameters stochastically; and by the time of detection the tumor has ~109 cells. During treatment, the patient initially responds and the tumor shrinks, but remaining cells inevitably develop mutations that give them drug resistance, and the tumor starts to grow again until the patient dies. It is becoming apparent that computational algorithms and mathematical frameworks can identify subtle patterns in patient profiles, which can help with early detection and personalized treatment, improving their outcome. For instance, we are developing mathematical frameworks to model tumor development and emergence of resistance against cancer drugs, using Galton Watson branching process - an area of stochastic processes, which also has applications in diverse areas (e.g. option pricing, predicting viral outbreak, news propagation on social networks). We are combining mathematical models with clinical data from cancer patients to ask some fundamental questions - (i) how long does it take a tumor to grow, and can we detect cancer early? (ii) can we identify emergence of resistance very early and accordingly change the treatment strategy? The project will aim to develop mathematical frameworks to model tumor growth using branching process.
Proficiency in computer programming (Java, C++, or python), familiarity with probability theory, concepts of stochastic processes, and optimization techniques are required. Knowledge in Biology is not required.
Data-driven precision medicine approaches to cancer
Project #: DC2017-11
Mentor: Subhajyoti De, Rutgers Cancer Institute of New Jersey
Abstract: One in four people is expected to develop cancer in their lifetime. No two patients are alike, and we need better strategies to detect cancer early, find right treatment for the patients, and monitor their outcome using a personalized medicine approach. Data science approaches using state-of-the-art computational algorithms and statistical frameworks can identify subtle patterns sifting through large amount of information in patient profiles, which can help with early detection and personalized treatment, improving their outcome. Within the scope of the Precision Medicine Initiative at the Rutgers Cancer Institute, for each patient we have troves of data on genetic mutations, and clinical and pathological reports. We are developing and implementing data science techniques to ask some fundamental questions - (i) can we distinguish aggressive tumor and treat patients accordingly? (ii) can we identify emergence of resistance very early and accordingly change the treatment strategy? The project will aim to develop data science frameworks to perform integrative analysis of cancer genomics and clinical data.
Proficiency in computer programming (Java, C++, or python), statistical analysis software (R or SAS), familiarity with concepts such as linear models, model selection, support vector machines are preferred. Knowledge in Biology is not required.
Anomaly detection in multi-layer networks
Project #: DC2017-12
Mentor: Lazaros Gallos, DIMACS & Rebecca Wright, DIMACS and Computer Science
Abstract: This project combines concepts from complex network science and cyber-security. Modern infrastructure is built as a network of networks. For example, the Internet depends on access to the power grid, which in turn depends on the power-grid communication network and the energy production network. Research in network anomaly detection systems has focused on single network structures (specifically, the Internet as a single network). The multi-layer structure, though, introduces novel phenomena and calls for new approaches. In this project, the student will study the behavior of existing distributed anomaly detection algorithms in a multi-layer structure.
Design and implementation of machine learning algorithms
Project #: DC2017-13
Mentor: Kevin Chen, Genetics
Abstract: We are working on machine learning methods for computational biology problems, specifically graphical models such as Hidden Markov Models and other similar models. The summer project will be to work with our group to design, implement and test a novel method on real biological data.
The main requirements needed for this project are a strong grasp of linear algebra, either statistics or probability theory, and computer programming ability. An interest in biology would be welcome but not necessary.
Data Stories: Knowledge Representation and Reasoning
Project #: DC2017-14
Mentor: James Abello, Computer Science & Mubbasir Kapadia, Computer Science & Periklis Papakonstantinou, Management Science and Information Systems
Abstract: Big Multi Medial Data is full of "big" potential. But as it increases in size and complexity, interacting with massive amounts of data in ways that are meaningful quickly escalates into an arduous undertaking. We would like to undertake the challenge of computer-human interactive exploration of information rich billion-scale "network" data sets. These include relationships on online social networks, who is buying what on online auctions, and intelligence analysis of communication patterns and network traffic.
The plan is to develop a prototype meta-system, in which users gradually build up an understanding of billion-scale network datasets where data is dynamic, and nonlinear. Users of the prototype should be able to summarize their understanding of the explored data set by producing a story that encapsulates the data set "evolution". Our emphasis will be on universal knowledge representations and reinforcement reasoning. This project will build up on Abello's current NSF funded work on "Computer-Human Graph Telediscovery" [NSF Award Number IIS-1563971] blended with Kapadia's expertise on symbolic knowledge and automated planning-based reasoning of media-agnostic data representations and Papakonstantinou's expertise on data streaming. The proposed prototype will be focused on Rutgers security related data and some recently released relevant data sets from some search companies. The goal is to provide users with digital exploration and data annotation tools that will amplify their reasoning capabilities about massive data sets summarization and synthesis.
Required Skills: Programming ability in Java and Java Script. Knowledge of OpenGl or WebGl.
Strong Background on Algorithms and Computer Graphics.
Visualization of Time-Varying Graphs
Project #: DC2017-15
Mentor: James Abello, Computer Science
Abstract: ASK-GraphView is a node-link-based graph visualization system that allows clustering and interactive navigation of large graphs [1]. The system constructs a hierarchy on an arbitrary, weighted, undirected input graph using a series of increasingly sophisticated clustering algorithms. Building on this earlier work, this project will address the problem of visualizing graphs that are being collected in a streaming fashion. A key challenge is to identify graph sub-structures and statistics on them that can be used as the basis to depict evolution of the graph through time [2]. Another goal is to devise a visualization algorithm that produces a layout that is stable over time, thus preserving a user's mental map.
References:
[1] Abello J, Ham FV, Krishnan N, "AskGraphView: A Large Graph Visualization System", IEEE Transactions in Visualization and Computer Graphics, 12(5) (2006), 669-676.
[2] Hu Y, Kobourov S, and Veeramoni S, "Embedding, Clustering and Coloring for Dynamic Maps", Proceedings of IEEE Pacific Visualization Symposium, (2012).
Projects in Pure Math
Project #: DC2017-16
Mentor: Faculty of the Math Department, Mathematics
Abstract: The Math REU Coordinator is Prof. Anders Buch. Several projects will be run in 2017 by members of the pure math faculty. Past topics have included Schubert Calculus (Buch), Ricci flow(Song), Mathematical Physics and General Relativity (Soffer), and mathematical Yang-Mills theory (Woodward).Applicants interested in a project in pure mathematics should list this project in their application and indicate their specific Math interests; further details on the projects will be worked out in the Spring.
Stadiums and Metal Detectors
Project #: DC2017-17
Mentor: Christie Nelson, Masters of Business and Science in Analytics and CCICADA
Abstract: When utilizing metal detectors at a large venue such as a sports stadium, there are the competing objectives of accuracy of the patron screening and the speed of throughput. This research, carried out in collaboration with large sports venues, analyzes the patron screening method of walk-through metal detectors ("walk-throughs"). Part of this project may involve on-site observations at stadium events.
Experimental design is the focus of the project, helping large venues better understand the performance of walk-throughs in real outdoor settings. Because of the number of experimental factors to be considered (type of item, location and height of object, orientation, speed of object passing through the machine, walk-through security setting, etc.), designing experiments require a sophisticated design tool called combinatorial experimental design. Experimental designs can focus on various questions, such as: does a walk-through catch each of the pre-specified prohibited test items; can multiple metal test objects can be hidden on a person and tested all at once in different height zones; how does human gait affect detection; etc.?
How to provide distributed differential privacy?
Project #: DC2017-18
Mentor: Muthu Muthukrishnan, Computer Science
Abstract: Can people provide information to a service that say recommends videos or music or other items based on your interests, without revealing too much about themselves? Is there a way to formalize this in a way we can reason about the tradeoffs? This project will explore sketch-based solutions for such problems.
Data-Driven Modeling and Applications for Human Mobility in Smart Cities
Project #: DC2017-19
Mentor: Desheng Zhang, Computer Science
Abstract: In the vision of smart cities, expanding our knowledge about human mobility is essential for building novel applications and services. Previous human mobility studies have typically been built upon survey and empirical single-source data (e.g., cellphone or transit data), which inevitably introduces a bias against residents not contributing this type of data. To address this issue, in this project, we aim to propose a novel data-driven modeling framework to explore human mobility and related novel applications using real-world multi-source data from two major cities, i.e., New York City in U.S and Shenzhen in China. The real-world data will be used in this project including data from cellphone, taxi, bus, bike, subway, truck, 311 calls, WiFi, and social networks, with millions of vehicles and residents. The REU students are expected to conduct original research from various data-driven perspectives. Related Details about this project can be found here.
Cross-Domain Internet of Things for Smart Cities
Project #: DC2017-20
Mentor: Desheng Zhang, Computer Science
Abstract: This project is focused on Data-Driven Internet-of-Things in Extreme-Scale Data-Intensive Urban Infrastructure from an Interdisciplinary perspective. From an Internet-of-Things prospective, the key objective of this project is to specify, detect, and utilize real-time interactions of cross-domain urban systems at individual device levels, i.e., transportation (e.g., taxis, buses, trucks, subways, bikes, personal & electric vehicles), telecommunication (e.g., cellphones), finance (e.g., smartcards), social networks (e.g., check-in and app logs), and geography (e.g., road networks) for various urban services. The potential Internet-of-Things platforms with data access are across 8 cities on 3 continents with 100 thousand app users, 500 thousand vehicles, 10 million phones, 16 million smartcards, and 100 million residents involved. The REU students are expected to conduct original research from various data-driven perspectives. Related Details about this project can be found here.
Authentication
Project #: DC2017-21
Mentor: Janne Lindqvist, Electrical and Computer Engineering
Abstract: Mobile authentication, despite myriad research proposals, has stagnated. Many of these proposed alternatives exist only to languish in publication without real-world application or testing -- most never make it out of computing software and on to a device! We are looking for students that are interested in helping us shore up the foundations of mobile authentication by doing rigorous and systematic work to establish clear, useful mobile authentication solutions that address usability, memorability, and security weaknesses inherent to PINs and passwords. Specifically, we want to establish clear metrics for gauging the security space of a solution, the usability benefits, and memorability through user studies. Our current work is focusing mostly on free-form gesture authentication, and we have a few projects on-going now, for example: weak subspace enumeration for security and attacking; usability and security assessments of template-based gestures. Students with backgrounds in CS, Mathematics, CE, and EE are encouraged to apply.
Password security
Project #: DC2017-22
Mentor: Janne Lindqvist, Electrical and Computer Engineering
Abstract: Passwords are the legacy log-on for desktop environments and have resisted attempts to be replaced. We instead are acknowledging their existence and wish to push forward with better understanding how to help users create and remember better passwords. We are looking for students that are interested in modeling usability and memorability of passwords as created by users and to help solve issues with multiple password interference. The end goal of projects in this space is to increase ways to help users create passwords without unfairly burdening them. Students with backgrounds in CS, CE, EE, and Psychology are encouraged to apply.
 Return to REU Home Page
Return to REU Home PageDIMACS Home Page
DIMACS Contact Information
Page last modified on January 31, 2017.